
META just pulled back the curtain on a new language model architecture called BLT - and no, it's not about your lunch order, though it might just be as satisfying....
It stands for Byte Latent Transformer, and it makes some pretty bold claims (and backs them up!) about efficiency and robustness that are definitely worth a closer look. It's already comparable with Llama 3 models while, on average, needing half the compute!
I’ve been digging into the research paper and the GitHub repository for BLT, and there’s some compelling stuff here. Let's break it down.
What the Paper Says: A Peek Under the Hood of BLT
The core innovation of BLT is its approach to processing text at the byte level rather than relying on traditional tokenization. Now, why is this a big deal? Tokenization, while standard, can sometimes be a bit clunky. It can struggle with out-of-vocabulary words, be sensitive to minor typos, and might not always capture the nuances of sub-word information.
BLT tackles this head-on. Here are the highlights from the paper:
- Dynamic Byte Patching: Instead of fixed tokens, BLT encodes bytes into dynamically sized "patches." The clever part? The segmentation of these patches is based on the entropy of the next byte. In simpler terms, it allocates more computational resources and model capacity where the data is more complex or unpredictable, and less where it's straightforward. This dynamic allocation is key to its efficiency.
- Architecture: The model isn't just one giant transformer. It cleverly combines smaller, byte-level local models and a larger global latent transformer. This modular design, coupled with lightweight encoders and decoders, effectively maps byte sequences to these latent patch representations.
- Efficiency Gains: This is where it gets really interesting for us, growth-minded folks. The paper reports that BLT can match the training flop-controlled performance of models like Llama 3 (up to the 8B scale) but, and this is a big but, it can do so with up to 50% fewer flops at inference. That’s a massive potential saving in compute, which means faster responses and lower operational costs. This is music to the ears for anyone looking to deploy LLMs at scale.
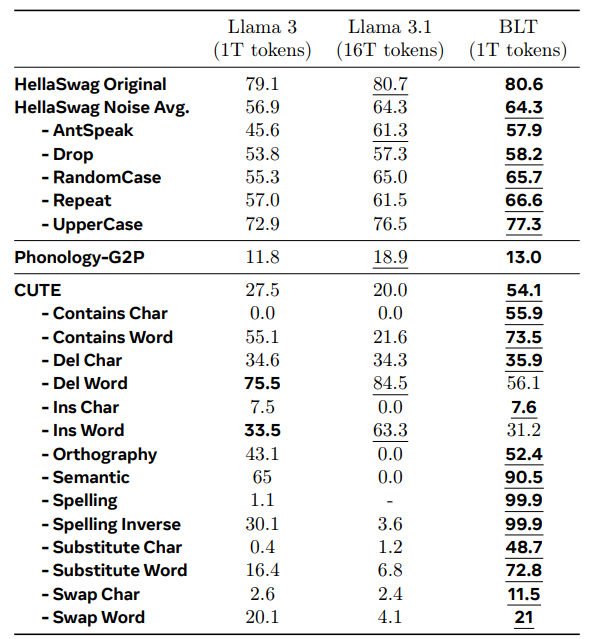
- Improved Robustness & Understanding: Working at the byte level gives BLT an edge in handling noisy input (think typos, slang, or unconventional language). The researchers also note qualitative improvements in reasoning and what they call "long-tail generalization," meaning it might be better at handling less common concepts or queries. It also shows an enhanced awareness of sub-word aspects, which could benefit various NLP tasks.
- New Scaling Dimension: The paper suggests BLT unlocks a new way to think about scaling LLMs - you could potentially scale the model size while keeping the inference budget fixed. This offers a different optimization path compared to just throwing more parameters at the problem.
What This Meta Release Means
So, Meta (under its Facebook Research banner) has published the paper and released the code on GitHub. This is significant for a few reasons:
- Pushing the Boundaries (and Sharing It): It's always encouraging to see major players like Meta contributing to the open-source AI community. Releasing the code allows researchers and developers worldwide to scrutinize, build upon, and potentially even improve the BLT architecture, fostering innovation across the board.
- Efficiency is King: The strong emphasis on inference efficiency clearly signals where the industry is heading. As LLMs become more pervasive, the ability to run them cost-effectively and with lower latency is paramount. BLT offers a promising approach to achieving this, which could accelerate the adoption of more powerful language models in a broader range of applications.
- Beyond Tokenization: BLT’s byte-level approach is a compelling exploration beyond standard tokenization methods. If it proves robust and scalable across various languages and tasks, it could significantly influence future LLM designs. We might see more models inherently adaptable to diverse and evolving text data.
- Potential for Broader Applications: More efficient and robust models open doors. Imagine more capable AI on edge devices, more sophisticated chatbots that handle typos with grace, or tools that can more effectively understand and process highly specialized or noisy text data. From a growth perspective, this means more opportunities to leverage AI in new and impactful ways.
Of course, it's still relatively early days for BLT. The real test will be how it performs in the wild, across many benchmarks, and when adopted by the broader community. But the initial findings presented in the paper are undeniably exciting.
Just check out this "simple" task that the majority of LLMs can't handle properly:
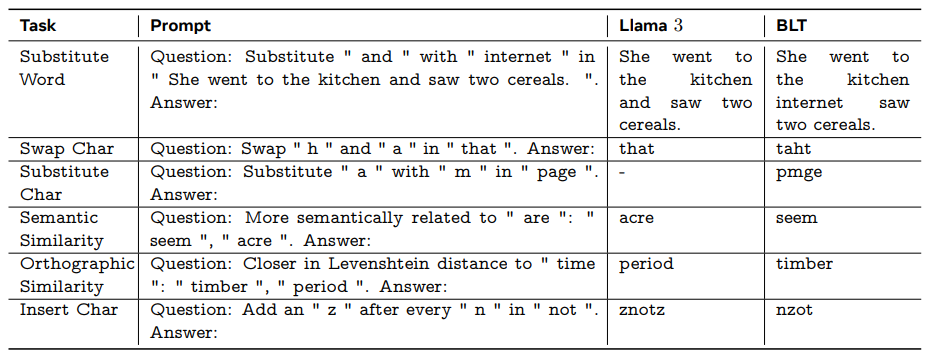
Meta's release of BLT is more than just another model; it's a statement about the future direction of language model development, emphasizing efficiency, robustness, and a deeper understanding of language at its most fundamental level. As someone keenly watching the AI space, this is one development I'll be tracking closely. It will be fascinating to see how BLT evolves and what the community builds with it.
What are your thoughts on byte-level processing and the potential of architectures like BLT?


