Brave Search runs on its own index. It does not borrow results from Google or Bing, which is what most other "private" search engines quietly do. That single fact reshapes how you get found on Brave, and most advice written for Google transfers to it BADLY. I read Brave's own documentation, the open-source code that builds its index, and the research papers behind it, then wrote this beast of an article (with a link on nearly every claim so you verify it).
One warning before anything else. A good share of the Brave SEO advice online is wrong... Be careful before following wild claims or paying for a fake indexing service.
What Brave Search is, and why that changes ranking
Brave Search did not start at Brave. Josep M. Pujol, Brave's chief of search, ran the search team at Cliqz, a German privacy search engine that closed in early 2020. Its search core survived as a spin-off called Tailcat, and Brave bought Tailcat in February 2021. The system that feeds Brave's index today, the Web Discovery Project, is a direct descendant of Cliqz's "Human Web", and Brave's own docs are completely open about it.
The independence is recent. In April 2023, Brave removed the last calls to Bing, and from that point, web results came entirely from Brave's own index. The Verge reported the same break. Brave still keeps an optional Google fallback-mixing setting, so "100% independent" describes the default path rather than every result you might ever see.
The index has enough volume to be worth your time. Brave Search passed 2.5 billion queries in its first year and later reported more than 8 billion annualized queries, running as the default engine in a browser used by tens of millions of people. A page that ranks here reaches a real audience.
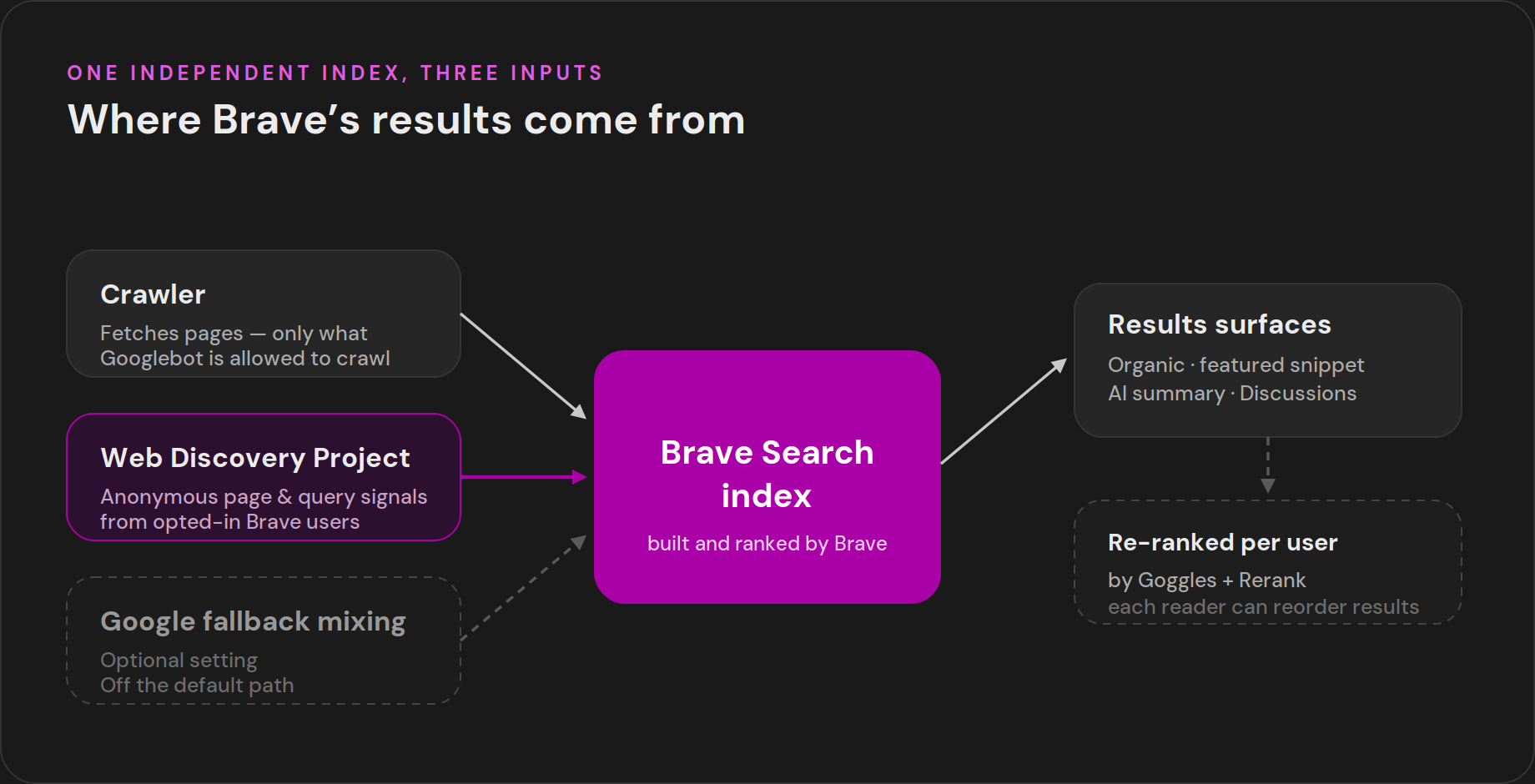
Two engines build that index. A crawler fetches pages the usual way. The Web Discovery Project collects anonymous signals from people actually browsing in the Brave browser. You need to understand both, because they reward different things.
How Brave's crawler works and what decides the eligibility of your website
Brave's crawler is quiet on purpose. Its crawler help page says the bot "does not advertise a differentiated user agent", because sites that allow only Google would block an honest Brave bot. The same page sets the rule that decides whether you can show up at all: if Googlebot cannot crawl a page, Brave's bot will not crawl it either.
Your Brave eligibility rides on your Google crawlability. There is no separate Brave allow-list to manage and no Brave-specific user agent to whitelist. Webmasters who went looking for one came up empty - a long-running WebmasterWorld thread reports no Brave string in server logs and a generic Chrome user agent, against a figure of roughly 40 million URLs crawled per day. So you cannot reliably spot Brave's index crawler in your access logs.
Robots.txt rules work in a way that trips people up. Per the same crawler page, robots.txt is not what keeps a page out of Brave's index. To remove a page, you add a noindex directive, and Brave applies it after it re-fetches the page. You can speed that re-fetch by submitting the URL at Brave's submit-url page. The Web Discovery Project honors the same signal - pages marked noindex get dropped before they ever reach Brave's servers.
There is a second, newer crawler worth knowing about. Bot-tracking services document Bravebot as Brave's AI-search crawler, the one that gathers pages for citations in Brave's AI answers. Unlike the stealthy index crawler, Bravebot can identify itself and respond to robots.txt user-agent tokens, so you can at least see it in logs and decide whether to allow it. Blocking it removes you from Brave's AI answers, which is the opposite of what most sites want in 2026.
There is no Brave Search Console
No dashboard, no ownership verification, no sitemap submission, no impressions or clicks report, no position tracking. A clear Hashmeta guide puts it plainly: Brave "does not yet offer a dedicated search console" like Google's or Bing's.
Now the correction I promised. A published Hot Brewed SEO post tells readers Brave offers a tool where site owners can "submit their sitemap directly, verify site ownership", and watch how Brave indexes them. No such tool exists, and the claim contradicts Brave's own crawler page. If you have been hunting for Brave's sitemap submission or a verification flow, stop - you are chasing something that was never built.
What does exist is the single re-fetch endpoint at search.brave.com/submit-url, and its real job is re-fetching and de-listing, not "add my new site". To confirm you are in the index, run site:yourdomain.com on search.brave.com and read your server-side referral logs. That is the whole toolkit.
How real visitors build Brave's index
This is the engine that makes Brave different, and it changes what you should put on a page. The project is open source, and the Web Discovery Project README contains real message payloads. Brave introduced the system in its search and web discovery announcement, and explains the user-facing side in its help center.
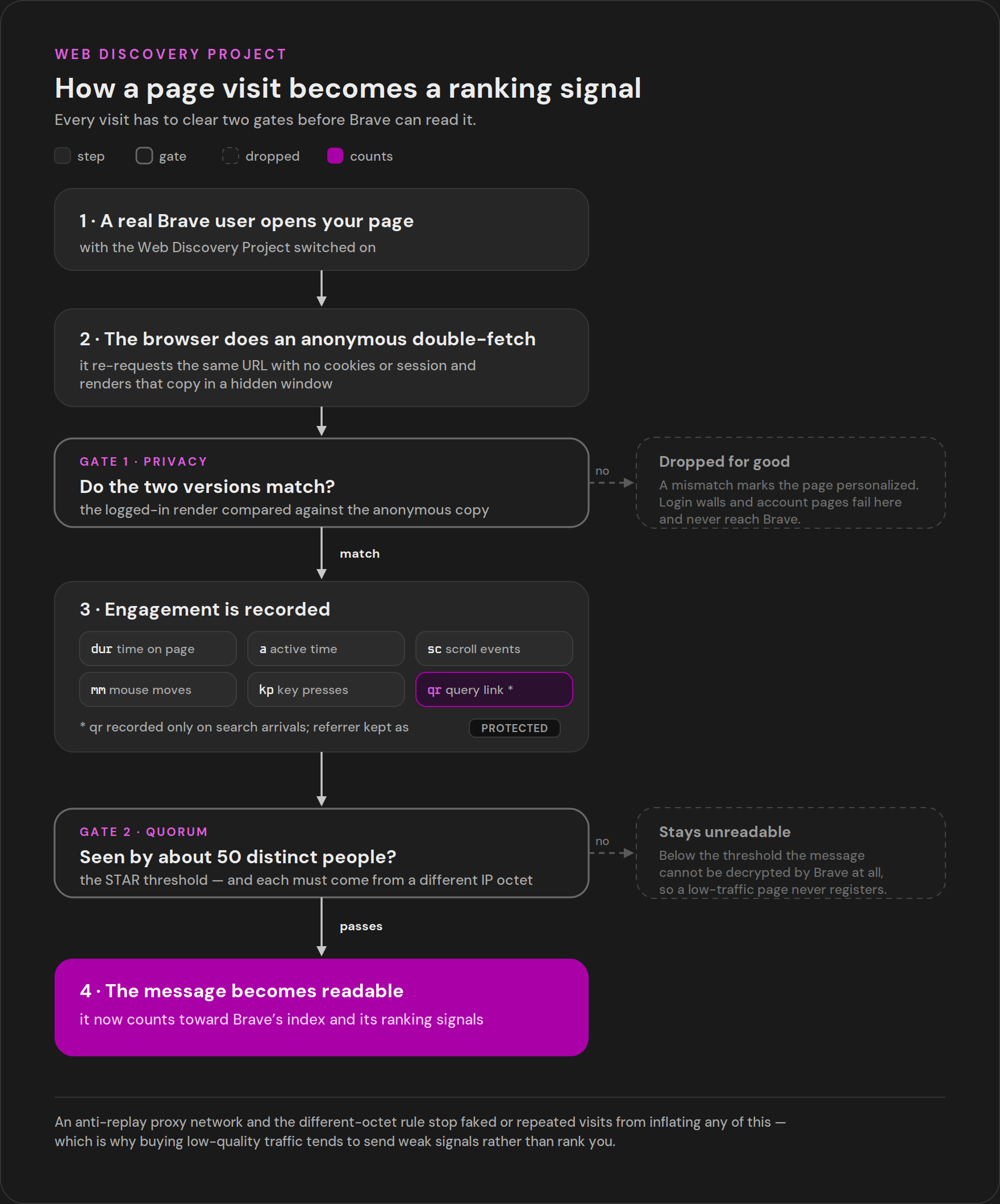
When a person opts in, their browser sends two kinds of anonymous messages. One fires when they land on a search results page. The other fires when they visit a normal page, and that second one carries the signals you care about.
Here is the page message, trimmed and annotated from the documented schema:
{
"type": "wdp",
"action": "page",
"payload": {
"url": "https://example.com/guide/",
"a": 14, // seconds the reader was active on the page
"dur": 25904, // total time on page, in milliseconds
"e": { "mm": 3, "sc": 3, "kp": 0 }, // mouse movements, scroll events, key presses
"x": { // structural signature from an anonymous re-fetch
"t": "Page title here",
"lt": 33993, // length of text with HTML stripped
"nl": 228, // number of links on the page
"ni": 6, // number of input fields
"nip": 0, // number of password fields
"canonical_url": "https://example.com/guide/"
},
"qr": { "q": "best private browser", "t": "go", "d": 1 } // the query that led here
},
"ver": "1.0",
"channel": "brave",
"ts": "20210817"
}
Read the fields and the ranking model starts to show through. The a value is active engaged time. The dur value is total dwell time in milliseconds. The e object counts mouse movement, scrolling, and key presses. The qr object, present only when someone arrived from a search, records the query, which engine they used, and the click depth. Brave records dwell time, scroll depth, and interaction as a proxy for whether a page was worth reading. Thin pages that lose readers in a few seconds send weak signals. Pages people stay on and scroll through send strong ones.
Now, the constraint that breaks a lot of modern sites. The page content Brave keeps is not what the logged-in reader saw. The system performs what the README calls a double fetch - a second, anonymous request to the same URL with no cookies or session, rendered in a hidden window, and the structural signature comes from that copy. If your real content only appears for logged-in users, or only after client-side JavaScript runs, the anonymous fetch sees a different or empty page, the signature mismatches, and the page can be flagged as private and dropped. Server-render the content that matters. A page that looks rich to a logged-in human but empty to an anonymous fetch is invisible to Brave's index.
The double fetch also screens out private pages by design. Login walls fail it because the anonymous request redirects to a sign-in or error page. Pages behind a private network get caught differently - the README describes detecting domains that resolve to private IP ranges and marking them private. None of this is something you tune. It is the boundary of what Brave will ever index.
A page also has to clear a popularity bar before Brave can read its message at all. The README describes a quorum check built on Brave's STAR protocol: the page message is encrypted with a key the server can only reconstruct once enough different people (the documented threshold has been around 50) have visited the same URL. Below that count, the content is mathematically unreadable to Brave. A brand-new page with no traffic is invisible until real visitors show up. And the system fights gaming directly. It sends only the last octet of each visitor's IP address and requires enough visitors with different octets, so a single office or home network cannot inflate a page's apparent popularity. An anti-replay proxy network sits in front of the whole thing to stop one user from replaying a message to fake demand. Services that promise to "send Brave signals" for your URLs are pushing against the exact mechanism Brave engineered to resist them.
The papers and code, if you want the source
Brave published most of this, which is rare. The privacy and quorum mechanics come from STAR: Secret Sharing for Private Threshold Aggregation Reporting, presented at ACM CCS 2022. You can read the paper PDF, the arXiv version, Brave's plain-language writeup, and the Rust and WASM code in the sta-rs repository. Brave is standardizing STAR at the IETF in its Privacy Preserving Measurements working group.
The anti-replay proxy network has its own paper, Preventing Attacks on Anonymous Data Collection. The lineage traces to Cliqz's Human Web overview and the short paper Data Collection without Privacy Side-Effects by Konark Modi and Josep Pujol, plus the related WhoTracks.Me study.
For the concrete numbers behind the algo, a Brave browser issue on Nebula lays out the differential-privacy parameters: derived from epsilon of 1 and delta of 10^-8, a sampling rate of about 0.105, with the aggregation threshold K set to 50. That 50 is the practical "enough different people" number you should keep in mind when you wonder why a low-traffic page never seems to register.
What Brave documents about ranking, and what SEOs only guess
Brave publishes no ranking-factor list the way Google scatters hints across its docs. What you can state from primary sources is narrow and solid: engagement signals from real visitors feed relevance, the popularity quorum gates whether a page even counts, and crawlability plus noindex decide eligibility. Brave's help docs also describe the project's aim as cutting noise and lifting results that match what people meant.
Everything more specific comes from SEO "gurus" reading the tea leaves, and you should treat it that way. A Ranktracker guide argues Brave leans on content trust and independence signals more than backlink volume, and rewards relevance, expertise, freshness, visible authorship, and clean crawlable HTML while pushing down pages that look mass-produced. That fits the architecture, but Brave has not confirmed it. A fact-check of Brave's independence claims notes that outside verification of Brave's index size, freshness, and spam resistance is thin, and that Brave's incentives are tied up with growing its browser and its opt-in program.
Speculation: Can paid traffic prime your ranking signal?
This section is my pure educated guess, not a documented behavior. Brave has not published how its ad traffic touches the index, so treat what follows as a working theory I find plausible from the mechanics, not as fact.
Start from one observation about the Web Discovery Project: it records a page visit, not the reason for the visit. A person who clicks a paid ad in Brave with the project enabled sends the same page message as a person who arrived from an organic result or typed the URL. The browser carries no notion of the intent behind the navigation. And because the visit is a real human action, it is not what the anti-replay proxy network and the IP-octet diversity check exist to stop - those filter faked or replayed signals, not genuine people who happened to start at an ad. A real ad click can feed the same kind of data a real organic click does.
Where the visits differ is in what the message carries, and that maps onto how the person arrived. A direct visit and an organic-click visit are not identical in the data. The page message holds a qr object - the query -> page link - that only fills in when the person came from a search. A direct visit sends engagement and popularity signals: the page was visited, someone stayed for some seconds, scrolled some number of times. An organic click sends that plus "this page was an answer to query Q".
The paid click sits in between, and this is the part Brave has never spelled out. The project watches browser navigation in a general way - it saw the user on a Brave results page for query Q, then on the destination page. If it records a paid click the same way it records an organic one, which it might since it is just observing a results-page-to-destination hop, then the paid click carries the query->page link too, and paid traffic could feed query-specific ranking rather than generic popularity. Brave serves its own search ads and knows which links on the page are paid, so it could instead exclude paid-click navigations from the organic signal to stop advertisers from buying their way up. That choice would leave a paid visit contributing to engagement and popularity, but no query vote. I cannot tell you which path Brave took, and that single undocumented decision is what separates "ads prime general visibility" from "ads buy a keyword".
Two things still make sense, whichever way it resolves. Engagement quality colors the signal - a paid click that bounces in two seconds sends a weak message, one that reads and scrolls sends a strong one - so the useful version is an engaged visit, not a click. And the cleanest, least speculative use of the whole idea is getting a page over the visitor threshold at all. A new page that cannot reach the roughly fifty distinct visitors the quorum needs can be pushed across it by real, varied ad traffic, at which point its messages become readable and the page starts to register in the signal. Paid traffic as a way to cross that line is the strongest form of the argument, and the one I would act on.
So... Why Brave ad and not any random traffic source? Because Brave ads guarantee visits from people who actually use Brave and will send the signal we need 😏
The four result surfaces you compete for
Ranking on Brave is not one list. The results page has four surfaces beyond plain organic links, and each picks content in its own way. Win these and you win Brave.
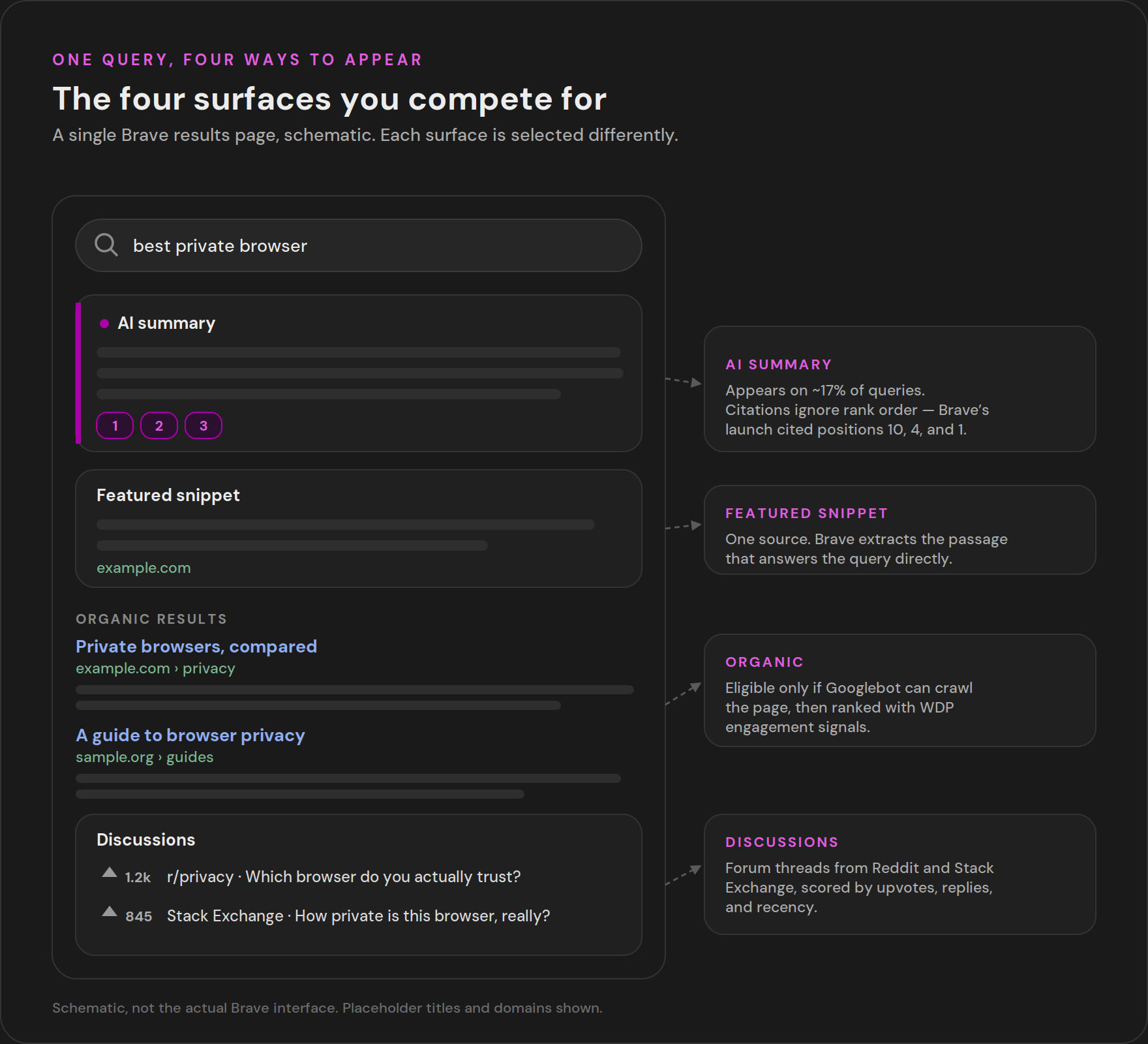
Featured Snippets
The closest thing to classic SEO. Brave's AI help page describes the case where one source answers a question well, and Brave will "extract the most relevant snippet of text" from that page to show up at the top. Write a clean, self-contained answer to a specific question, high on the page, and you become the thing it extracts.
AI Summarizer and AI Answers
This is the surface that behaves least like organic rank. Brave's Summarizer announcement describes a system built in-house, not on OpenAI, made of three models: one that pulls a concrete answer out of text snippets, an ensemble of classifiers that score candidates for things like hate speech, vulgarity (I'm screwed here), and spam (and here...), and a final model that rewrites for readability. The classifier stage is a gate. Content that trips the spam or vulgarity scoring gets filtered out of citations, no matter how relevant it is, so clean writing is not optional if you want to be cited.
Citation selection does not follow organic position. In Brave's own launch example, reported by Search Engine Land, the three citations came from organic positions 10, 4, and 1, and summaries showed for about 17% of queries at launch. BleepingComputer's writeup confirms the three-stage model. Being the single best direct answer to a question matters more for getting cited than sitting at the top of the list. Aim the page at the question, and put the answer where a model can lift it.
Ask Brave and its enrichments
Brave's AI help page describes Ask Brave as the longer-form mode, with chat follow-ups, a deep-research option, and contextual extras like videos, news, products, businesses, and shopping. Those extras are more places to appear. Structured data and being present in the relevant verticals: product feeds, business listings, video - are how you land in them.
Discussions
The most underrated channel, and the easiest to act on. When Brave judges a query worth a conversation, it pulls forum results from sites like Reddit and StackExchange straight into the page, as covered in its search anniversary post. The selection logic is spelled out by MediaPost: a discussion-worthiness score built from the recency and popularity of the topic, the engagement on the conversation measured by upvotes and replies, and a relevance score against the query. Brave frames Discussions partly as a counter to SEO spam - surfacing real human threads instead of optimized pages. For product, travel, and how-to queries, a genuinely upvoted, recent, on-topic Reddit or StackExchange thread can put you on the Brave results page even when your own domain does not rank. Treat forum presence as a first-class part of your Brave plan, not an afterthought.
Becoming native where Brave users already gather
The paid version of this has a limit - clicks stop when the budget does. The durable version is being a real presence in the places Brave users already spend time, which feeds two things at once: the genuinely engaged visits the Web Discovery Project rewards, and the forum threads that Brave's Discussions surface pulls onto its results page. A contributor whose answers get upvoted is doing organic Brave SEO, whether they meant to or not.
I want to be straight about the data here... because it does not exist 🥸 Nobody can publish a Brave-share-by-community number - the browser's anti-tracking design is the reason such a dataset can't be built. So the list below is reasoning from who Brave users demonstrably are, not a headcount, and you should validate it rather than trust it.
The profile is narrow. Brave skews heavily male and young, and the people who go out of their way to install it tend to be developers, privacy-minded, and on the affluent side. Reviews keep landing on the same split audience: privacy users and Web3 users who want the built-in wallet. The crypto half is the part unique to Brave, since other privacy browsers cover the privacy half, so the densest concentration sits where the two interests overlap.
Closest to the source are the Brave-native and crypto spaces: r/brave_browser, r/BATProject for the token, and the community.brave.com forum, alongside crypto rooms like r/CryptoCurrency and r/ethereum and newsletters such as Bankless and The Defiant. These are the highest-density and the smallest, and they only pay off if your subject genuinely fits them.
The privacy communities are larger and warmer to outside contribution. Privacy Guides runs a busy forum and a Matrix room and lists Brave among its short set of recommended browsers. Techlore has the same setup with a large following. On Reddit there's r/privacy, r/degoogle, and r/browsers. One caveat keeps this from being a clean win: the privacy-absolutist end of this world is split on Brave. The crowd around Mullvad, LibreWolf, and GrapheneOS often distrusts Brave's for-profit, token-funded model and points people elsewhere, so those rooms carry fewer Brave users than the pragmatic-privacy rooms do.
To reach these people through someone they already trust, the privacy educators are the route. Naomi Brockwell's NBTV names Brave as her own browser of choice, and her audience reflects it. The same lane includes Techlore, Mental Outlaw, Rob Braxman, and The Hated One. On the crypto side, a placement in Bankless, Milk Road, or The Defiant reaches a Brave-heavy readership. Contributing or sponsoring here buys the audience by context, which sidesteps the fact that no ad platform lets you target the browser directly.
A looser ring of developer and decentralization spaces carries high Brave awareness at lower density: Hacker News, Lobsters, and dev.to given the engineer skew, plus the self-hosting and ad-block crowd at r/selfhosted, r/pihole, and r/uBlockOrigin. The fediverse - Mastodon and Lemmy - shares Brave's anti-Big-Tech leaning, with the same split that some of them prefer Firefox forks.
Participation is the whole point, not posting links. Brave's Discussions surface weights threads by upvotes, replies, and recency, so what reaches the results page is a genuinely useful answer the community lifted, not a drive-by promotion that got buried. Being the person who actually helps in these rooms is what produces both the surfaced thread and the engaged Brave visit behind it. You can check whether any of it works: detect Brave on your landing pages with navigator.brave.isBrave(), segment your analytics by referral source, and read the real Brave share each community sends next to how long those visitors stay. The rooms that send Brave traffic that reads and scrolls are the ones worth your hours, the rest you can drop without guessing.
Goggles and Rerank: the ranking you do not control
Two features mean there is no single fixed order to rank against. Brave introduced Goggles in June 2022 as shareable re-ranking rules, then added Rerank in January 2025. Rerank lets any user thumb a domain up or down, the change sticks for that person, and Brave's own AI answers then pulls some of their sources from the reranked results. So a single user can boost you, bury you, or remove you, and the AI layer follows.
Goggles scale that up. The rules are simple, and the Goggles API documentation shows the syntax:
! name: Tech Blogs
! description: Boost results from popular tech blogs
$boost=3,site=dev.to
$boost=3,site=medium.com
$downrank=5,site=w3schools.com
$discard,site=spam-example.com
When a boost and a downrank both match the same URL, the boost wins. You can write your own from the Goggles quickstart repo. The reason this matters for ranking: popular public Goggles can lift or sink whole categories of sites. gHacks covered the launch set, which included a Tech Blogs booster, a Hacker News Goggle that prioritizes community-favored domains while cutting the 1,000 most-viewed sites, and a No Pinterest filter that discards Pinterest entirely. The pattern is consistent - content farms and aggregators are what these Goggles downrank or discard, and independent, niche, expert sites are what they boost. You cannot control which Goggle a given person runs, but being the kind of site enthusiasts boost rather than bury is a real, if indirect, advantage that Brave's design hands to genuine publishers.
Measuring Brave when you mostly cannot
The privacy design that makes Brave appealing is the same design that makes a Brave rank tracker close to impossible. There is no per-user, per-query data to scrape, and the index does not hand out position data the way a Google results page does. So your measurement is indirect and you should accept that going in.
Run site:yourdomain.com on search.brave.com to confirm inclusion and spot which pages are in. Read your server-side referral logs for traffic coming from search.brave.com, since client-side analytics misses privacy-minded users who block scripts. Watch your logs for Bravebot to see whether the AI crawler is visiting. Third-party tools like Similarweb and Semrush will profile search.brave.com itself - its traffic, top keywords, referrers - but they cannot show your rankings inside Brave's index, so do not mistake one for the other.
Be skeptical of anything promising precise Brave rank tracking or guaranteed indexing. A rapid-indexing service claims it sends Web Discovery Project signals alongside its submissions and that higher signal counts read as popularity to Brave. Set that against the quorum threshold of 50 distinct visitors, the different-IP-octet requirement, and the anti-replay proxy network, and you can see the architecture was built to ignore manufactured popularity. Whether such services move anything is unverified, and the mechanism is designed to discount them.
The Brave playbook
Here is what I would do, in the order I would do it:
Get your pages flawlessly crawlable by Googlebot, because that is the hard gate for Brave. Clean robots.txt, no accidental noindex, a valid sitemap for your own hygiene even though Brave will not read it as a submission, fast loads, and content that is server-rendered so an anonymous, logged-out fetch sees the same page a reader does. Reserve noindex for pages you want out of Brave, and use the submit-url tool to push a re-fetch after changes or removals.
Write direct, self-contained answers to specific questions, placed high on the page, because that single passage is what feeds both Featured Snippets and the Summarizer's answer-extraction model. Keep the prose clean - the Summarizer's classifier stage filters spammy or vulgar candidates out of citations entirely, so a sloppy page loses the AI surface even when it is relevant.
Build a real presence on Reddit and StackExchange, since genuinely upvoted, recent, on-topic threads surface through Discussions on exactly the commercial and how-to queries you want, and Brave is weighting them on purpose to push past optimized spam.
Go past the generic forums to the rooms where Brave users actually concentrate — the privacy and crypto communities mapped earlier, from Privacy Guides and r/privacy to r/CryptoCurrency and the Brave-native subs. Be a real contributor there rather than a poster of links, because the upvoted, genuinely helpful thread is the one Discussions surfaces, and the people who open it skew heavily toward Brave. Where direct participation does not fit your product or your hours, reach the same readers through the privacy educators and crypto newsletters they already follow.
Add structured data for products, businesses, reviews, and video to qualify for Ask Brave's enrichment slots, and earn the dwell time that the page message rewards by making pages worth staying on. Drive engaged traffic from actual Brave users, because their time-on-page, scrolling, and interaction are a direct input and help a page clear the popularity quorum.
Measure which of these channels actually delivers, rather than trusting any ranking of them, mine included. Detect Brave on your landing pages with navigator.brave.isBrave(), tag sessions by referral source, and read the Brave share against dwell and scroll. Put more behind the channels where Brave traffic both shows up and stays, and if you test paid traffic to push a new page over its visitor threshold, hold it to the same bar - an engaged visit counts, a bounce does not.
The throughline across all of it is that Brave pays off pages people actually read and forwards, and it spent real cryptographic effort making sure you cannot fake that. The sites that win here are the ones that would deserve to win if no one were keeping score.


